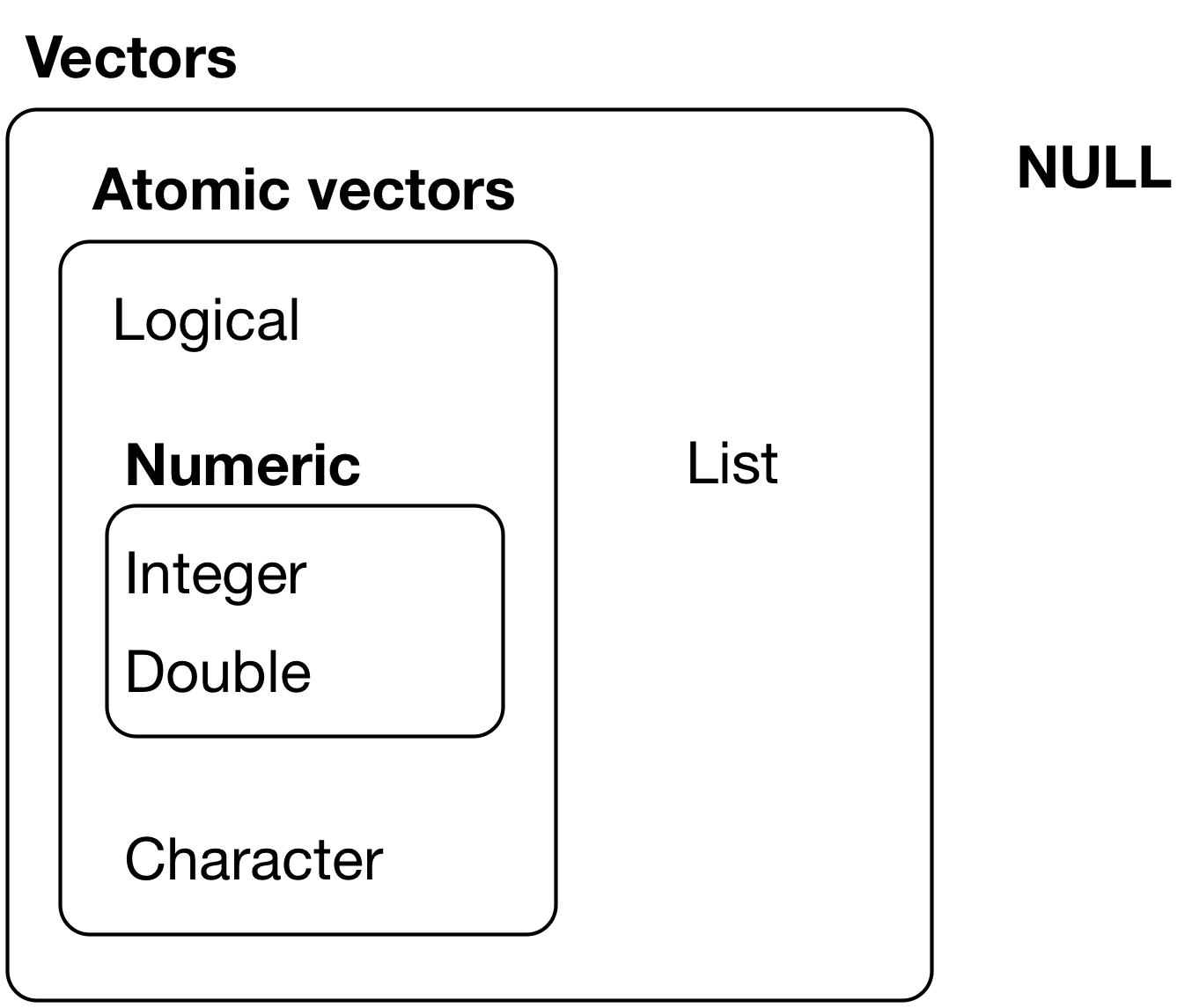
- A data frame is a list of atomic vectors of the same length, but not necessarily the same data type
- the
loans data frame has columns that are integer and factor types
> loans <- read.csv("https://raw.githubusercontent.com/mgelman/data/master/CreditData.csv")
> class(loans)
[1] "data.frame"
> typeof(loans)
[1] "list"
> str(loans)
'data.frame': 1000 obs. of 21 variables:
$ Status.of.existing.checking.account : Factor w/ 4 levels "... < 0 DM","... >= 200 DM / salary assignments for at least 1 year",..: 1 3 4 1 1 4 4 3 4 3 ...
$ Duration.in.month : int 6 48 12 42 24 36 24 36 12 30 ...
$ Credit.history : Factor w/ 5 levels "all credits at this bank paid back duly",..: 2 4 2 4 3 4 4 4 4 2 ...
$ Purpose : Factor w/ 10 levels "business","car (new)",..: 8 8 5 6 2 5 6 3 8 2 ...
$ Credit.amount : int 1169 5951 2096 7882 4870 9055 2835 6948 3059 5234 ...
$ Savings.account.bonds : Factor w/ 5 levels ".. >= 1000 DM",..: 5 2 2 2 2 5 4 2 1 2 ...
$ Present.employment.since : Factor w/ 5 levels ".. >= 7 years",..: 1 3 4 4 3 3 1 3 4 5 ...
$ Installment.rate.in.percentage.of.disposable.income : int 4 2 2 2 3 2 3 2 2 4 ...
$ Personal.status.and.sex : Factor w/ 4 levels "female : divorced/separated/married",..: 4 1 4 4 4 4 4 4 2 3 ...
$ Other.debtors.guarantors : Factor w/ 3 levels "co-applicant",..: 3 3 3 2 3 3 3 3 3 3 ...
$ Present.residence.since : int 4 2 3 4 4 4 4 2 4 2 ...
$ Property : Factor w/ 4 levels "if not A121 : building society savings agreement/life insurance",..: 3 3 3 1 4 4 1 2 3 2 ...
$ Age.in.years : int 67 22 49 45 53 35 53 35 61 28 ...
$ Other.installment.plans : Factor w/ 3 levels "bank","none",..: 2 2 2 2 2 2 2 2 2 2 ...
$ Housing : Factor w/ 3 levels "for free","own",..: 2 2 2 1 1 1 2 3 2 2 ...
$ Number.of.existing.credits.at.this.bank : int 2 1 1 1 2 1 1 1 1 2 ...
$ Job : Factor w/ 4 levels "management/ self-employed/highly qualified employee/ officer",..: 2 2 4 2 2 4 2 1 4 1 ...
$ Number.of.people.being.liable.to.provide.maintenance.for: int 1 1 2 2 2 2 1 1 1 1 ...
$ Telephone : Factor w/ 2 levels "none","yes, registered under the customers name": 2 1 1 1 1 2 1 2 1 1 ...
$ foreign.worker : Factor w/ 2 levels "no","yes": 2 2 2 2 2 2 2 2 2 2 ...
$ Good.Loan : Factor w/ 2 levels "BadLoan","GoodLoan": 2 1 2 2 1 2 2 2 2 1 ...